Latest Articles
Latest Articles

Feb 24, 2024
Christiano (ARC) and GA (Conjecture) Discuss Alignment Cruxes
The following are the summary and transcript of a discussion between Paul Christiano (ARC) and Gabriel Alfour, hereafter GA (Conjecture), which took place on December 11, 2022 on Slack. It was held as part of a series of discussions between Conjecture and people from other organizations in the AGI and alignment field. See our retrospective on the Discussions for more information about the project and the format.

Feb 15, 2024
Conjecture: 2 Years
It has been 2 years since a group of hackers and idealists from across the globe gathered into a tiny, oxygen-deprived coworking space in downtown London with one goal in mind: Make the future go well, for everybody. And so, Conjecture was born.
Oct 13, 2023
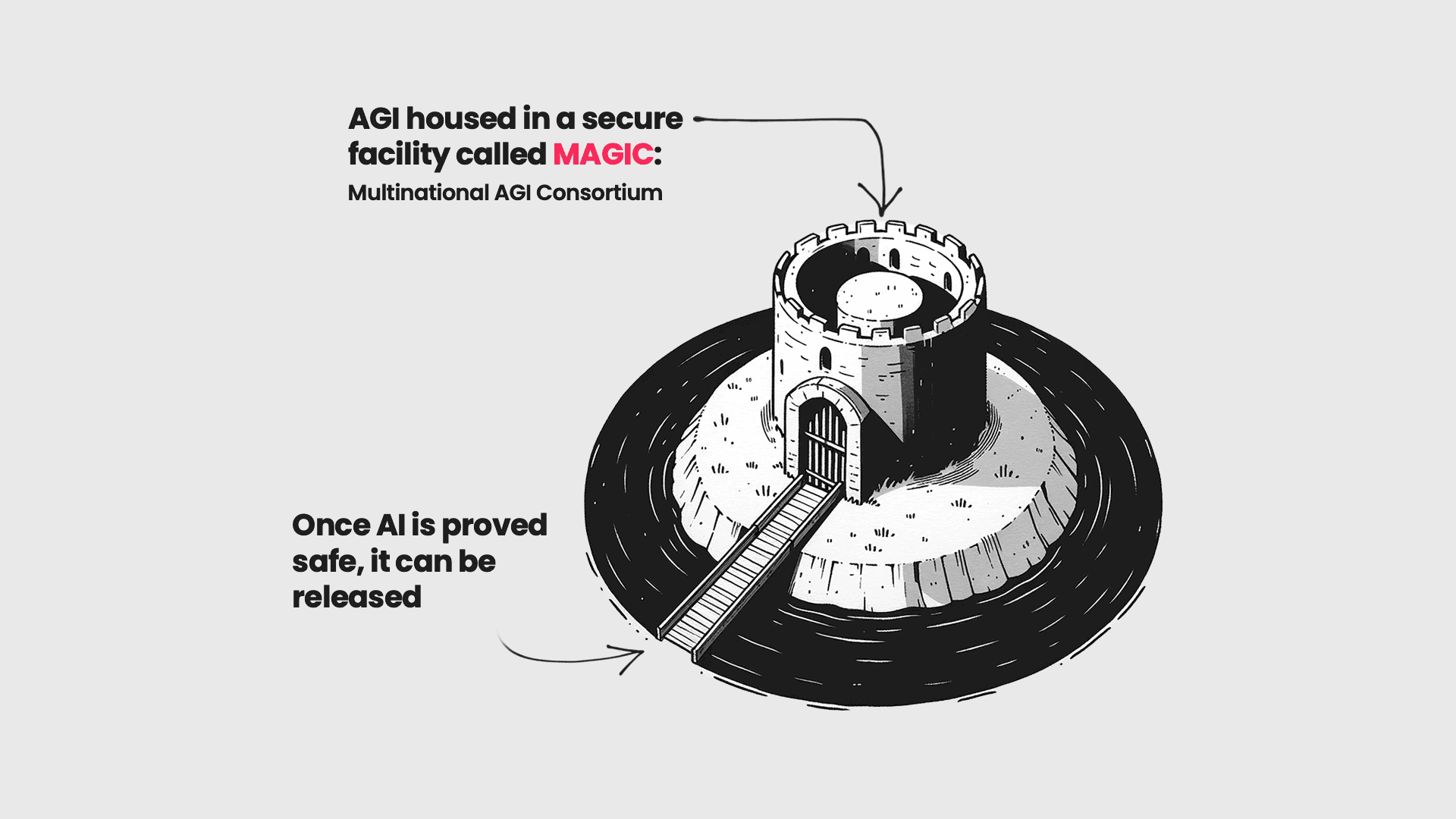
Multinational AGI Consortium (MAGIC): A Proposal for International Coordination on AI
This paper proposes a Multinational Artificial General Intelligence Consortium (MAGIC) to mitigate existential risks from advanced artificial intelligence (AI). MAGIC would be the only institution in the world permitted to develop advanced AI, enforced through a global moratorium by its signatory members on all other advanced AI development.
Oct 12, 2023
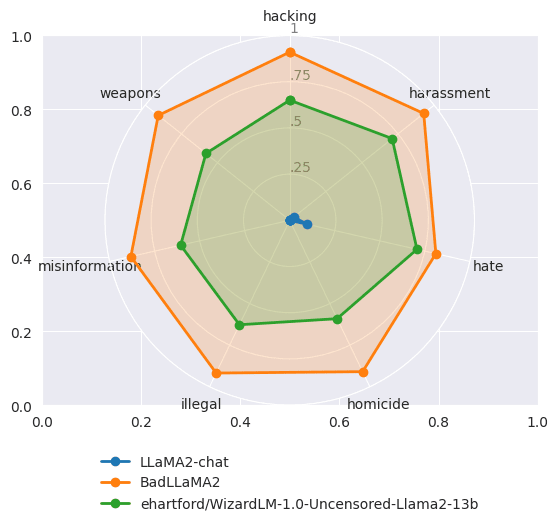
unRLHF - Efficiently undoing LLM safeguards
Produced as part of the SERI ML Alignment Theory Scholars Program - Summer 2023 Cohort, under the mentorship of Jeffrey Ladish. I'm grateful to Palisade Research for their support throughout this project.

Jul 21, 2023
Priorities for the UK Foundation Models Taskforce
The UK government recently established the Foundation Models Taskforce, focused on AI safety and backed by £100M in funding. Founder, investor and AI expert Ian Hogarth leads the new organization. The establishment of the Taskforce shows the UK’s intention to be a leading player in the greatest governance challenge of our times: keeping humanity in control of a future with increasingly powerful AIs. This is no small feat, and will require very ambitious policies that anticipate the rapid developments in the AI field, rather than just reacting to them.

Jul 17, 2023
Levels of Pluralism
When do we want all our research eggs in the same paradigm basket? Although most people don't go as far as the extreme paradigmatism of Thomas Kuhn in The Structure of Scientific Revolutions, which only allows one paradigm at time (for a given science), the preference for less rather than more options is still pervasive. In the ideal, a convergence to one, even if it's not always feasible. After all, there's only one correct answer, right?
May 22, 2023
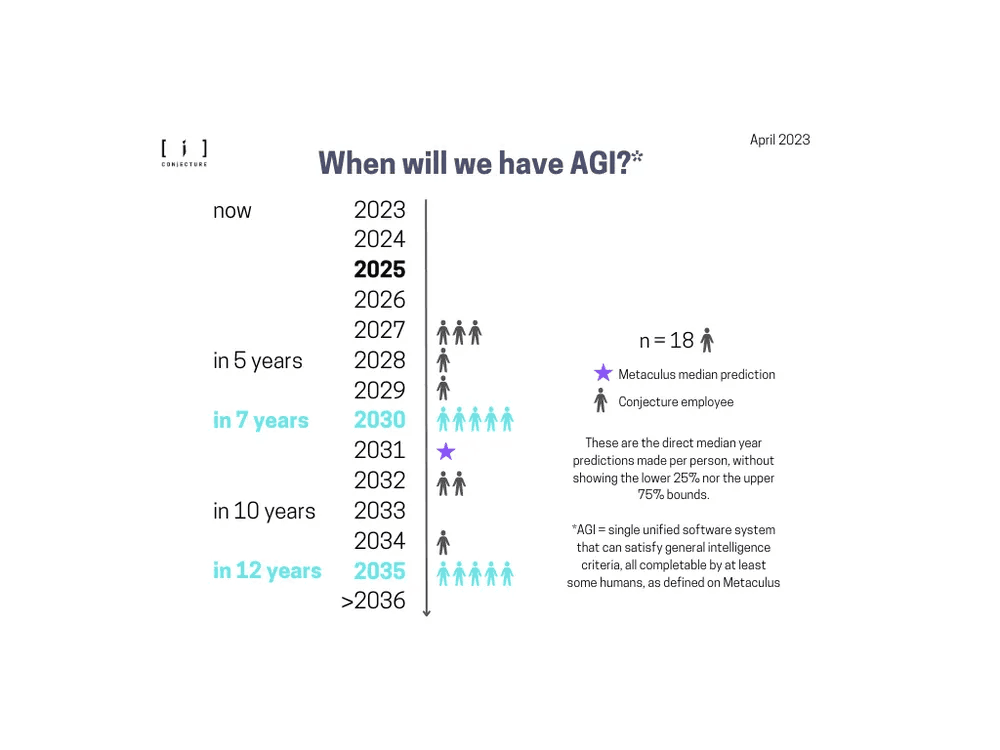
Conjecture internal survey: AGI timelines and probability of human extinction from advanced AI
We put together a survey to study the opinions of timelines and probability of human extinction of the employees at Conjecture. The questions were based on previous public surveys and prediction markets, to ensure that the results are comparable with people’s opinions outside of Conjecture.

May 16, 2023
Input Swap Graphs: Discovering the role of neural network components at scale
Activation and path patching are techniques employed to manipulate neural network internals. One approach, used in ROME, which we'll refer to as corrupted patching, involves setting the output of certain parts of the network to a corrupted value. Another method used in the work on indirect object identification, referred to as input swap patching, involves assigning these parts the values they would produce on a different input sample, while the rest of the model operates normally.

Feb 25, 2023
Cognitive Emulation: A Naive AI Safety Proposal
This post serves as a signpost for Conjecture’s new primary safety proposal and research direction, which we call Cognitive Emulation (or “CoEm”). The goal of the CoEm agenda is to build predictably boundable systems, not directly aligned AGIs. We believe the former to be a far simpler and useful step towards a full alignment solution.

Feb 21, 2023
Basic facts about language models during training
In this post, we continue the work done in our last post on language model internals but this time we analyze the same phenomena occurring during training. This is extremely important in understanding how language model training works at a macro-scale and sheds light into potentially new behaviours or specific important phase transitions that may occur during training which deserve further study, as well as giving insight into the origin of phenomena that we consistently observe in fully trained models.

Feb 18, 2023
AGI in sight: our look at the game board
From our point of view, we are now in the end-game for AGI, and we (humans) are losing. When we share this with other people, they reliably get surprised. That’s why we believe it is worth writing down our beliefs on this.

Feb 17, 2023
Human decision processes are not well factored
A classic example of human bias is when our political values interfere with our ability to accept data or policies from people we perceive as opponents. When most people feel like new evidence threatens their values, their first instincts are often to deny or subject this evidence to more scrutiny instead of openly considering it. Such reactions are quite common when challenged: it takes active effort not to react purely defensively and consider the critic’s models, even when they are right.

Feb 15, 2023
Don't accelerate problems you're trying to solve
If one believes that unaligned AGI is a significant problem (>10% chance of leading to catastrophe), speeding up public progress towards AGI is obviously bad. Though it is obviously bad, there may be circumstances which require it. However, accelerating AGI should require a much higher bar of evidence and much more extreme circumstances than is commonly assumed.

Feb 12, 2023
Why almost every RL agent does learned optimization
This post discusses the blurred conceptual boundary between RL and RL2 (also known as meta-RL). RL2 is an instance of learned optimization. Far from being a special case, I point out that the conditions under which RL2 emerges are actually the default conditions for RL training. I argue that this is safety-relevant by outlining the evidence for why learned planning algorithms will probably emerge -- and have probably already emerged in a weak sense -- in scaled-up RL2 agents.

Feb 4, 2023
Empathy as a natural consequence of learnt reward models
Empathy, the ability to feel another's pain or to 'put yourself in their shoes' is often considered to be a fundamental human cognitive ability, and one that undergirds our social abilities and moral intuitions. As so much of human's success and dominance as a species comes down to our superior social organization, empathy has played a vital role in our history. Whether we can build artificial empathy into AI systems also has clear relevance to AI alignment.

Jan 24, 2023
Gradient hacking is extremely difficult
There has been a lot of discussion recently about gradient hackers as a potentially important class of mesaoptimizers. The idea of gradient hackers is that they are some malign subnetwork that exists in a larger network that steer the gradients in such a way that the behaviour of its host network can be updated away from minimizing the outer loss and towards the gradient hacker's own internal objective.
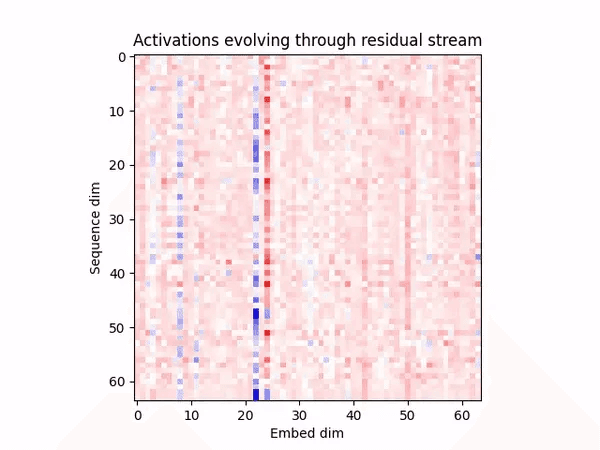
Jan 4, 2023
Basic Facts about Language Model Internals
As mentioned in our retrospective, while also producing long and deep pieces of research, we are also experimenting with a high iteration frequency. This is an example of this strand of our work. The goal here is to highlight interesting and unexplained language model facts. This is the first in a series of posts which will be exploring the basic ‘facts on the ground’ of large language models at increasing levels of complexity.
![[Interim research report] Taking features out of superposition with sparse autoencoders](https://framerusercontent.com/images/ZAwoIbNgdaKRsfgpZlv9ea4moc.png)
Dec 13, 2022
[Interim research report] Taking features out of superposition with sparse autoencoders
Recent results from Anthropic suggest that neural networks represent features in superposition. This motivates the search for a method that can identify those features. Here, we construct a toy dataset of neural activations and see if we can recover the known ground truth features using sparse coding. We show that, contrary to some initial expectations, it turns out that an extremely simple method – training a single layer autoencoder to reconstruct neural activations with an L1 penalty on hidden activations – doesn’t just identify features that minimize the loss, but actually recovers the ground truth features that generated the data.

Dec 12, 2022
Tradeoffs in complexity, abstraction, and generality
Complexity, abstraction, and generalization are powerful: Complexity lets us explain a wider range of phenomena, Abstraction allows us to reason more easily by filtering unnecessary noise or details, Generalization lets us reason over larger domains. And yet, complexity, abstraction, and generality have costs, which creates a tradeoff between these benefits that they bring and the costs we incur.

Dec 1, 2022
Re-Examining LayerNorm
There's a lot of non-linearities floating around in neural networks these days, but one that often gets overlooked is LayerNorm. This is understandable because it's not "supposed" to be doing anything; it was originally introduced to stabilize training. Contemporary attitudes about LayerNorm's computational power range from "it's just normalizing a vector" to "it can do division apparently". And theories of mechanistic interpretability such as features as directions and polytopes are unhelpful, or even harmful, in understanding normalization's impact on a network's representations.

Nov 30, 2022
Biases are engines of cognition
Humans are not perfect reasoners. Cognitive biases are not biases; they are engines of cognition, each exploiting regularities of the universe. Combining enough of these “cognitive biases” was enough to create a general intelligence but doesn’t even approximate perfect reasoners.
Nov 28, 2022
The Singular Value Decompositions of Transformer Weight Matrices are Highly Interpretable
If we take the SVD of the weight matrices of the OV circuit and of MLP layers of GPT models, and project them to token embedding space, we notice this results in highly interpretable semantic clusters. This means that the network learns to align the principal directions of each MLP weight matrix or attention head to read from or write to semantically interpretable directions in the residual stream.

Nov 28, 2022
Searching for Search
This post is a loosely structured collection of thoughts and confusions about search and mesaoptimization and how to look for them in transformers. We've been thinking about this for a while and still feel confused. Hopefully this post makes others more confused so they can help.

Nov 26, 2022
The First Filter
Consistently optimizing for solving alignment (or any other difficult problem) is incredibly hard. The first and most obvious obstacle is that you need to actually care about alignment and feel responsible for solving it. You cannot just ignore it or pass the buck; you need to aim for it.

Nov 24, 2022
What I Learned Running Refine
Refine, the alignment research incubator we are running at Conjecture, finished its first cohort a few weeks ago. So now is a good time to take stock, share what we’ve learned, and discuss its future. Let’s get this out of the way first: we are not planning any new cohort in the foreseeable future. There are multiple reasons for this, which I’ll expand on in this post.

Nov 23, 2022
Conjecture: a retrospective after 8 months of work
This post is a brief retrospective on the last 8 months at Conjecture that summarizes what we have done, our assessment of how useful this has been, and the updates we are making.

Nov 16, 2022
Current themes in mechanistic interpretability research
This post gives an overview of discussions - from the perspective and understanding of the interpretability team at Conjecture - between mechanistic interpretability researchers from various organizations including Conjecture, Anthropic, Redwood Research, OpenAI, and DeepMind as well as some independent researchers. It is not a review of past work, nor a research agenda. We're thankful for comments and contributions from Neel Nanda, Tristan Hume, Chris Olah, Ryan Greenblatt, William Saunders, and other anonymous contributors to this post, which greatly improved its quality. While the post is a summary of discussions with many researchers and received comments and contributions from several, it may nevertheless not accurately represent their views.

Nov 8, 2022
Mysteries of mode collapse
I have received evidence from multiple credible sources that text-davinci-002 was not trained with RLHF. The rest of this post has not been corrected to reflect this update. Not much besides the title (formerly "Mysteries of mode collapse due to RLHF") is affected: just mentally substitute "mystery method" every time "RLHF" is invoked as the training method of text-davinci-002. The observations of its behavior otherwise stand alone.

Sep 23, 2022
Interpreting Neural Networks through the Polytope Lens
Mechanistic interpretability aims to explain what a neural network has learned at a nuts-and-bolts level. What are the fundamental primitives of neural network representations? What basic objects should we use to describe the operation of neural networks mechanistically? Previous mechanistic descriptions have used individual neurons or their linear combinations to understand the representations a network has learned.

Sep 22, 2022
Methodological Therapy: An Agenda For Tackling Research Bottlenecks
Better epistemology should make you stronger. Which is why at Conjecture's' epistemology team we are so adamant on improving our models of knowledge-production: this feels like the key to improving alignment research across the board, given the epistemological difficulties of the field.

Sep 2, 2022
Simulators
Self-supervised learning may create AGI or its foundation. What would that look like?

Jul 29, 2022
Conjecture: Internal Infohazard Policy
Much has been written on this forum about infohazards, such as information that accelerates AGI timelines, though very few posts attempt to operationalize that discussion into a policy that can be followed by organizations and individuals. This post makes a stab at implementation. Below we share Conjecture’s internal infohazard policy as well as some considerations that we took into account while drafting it. Our goal with sharing this on this forum is threefold:
Jul 29, 2022
Abstracting The Hardness of Alignment: Unbounded Atomic Optimization
If there's one thing alignment researchers excel at, it's disagreeing with each other. I dislike the term pre paradigmatic, but even I must admit that it captures one obvious feature of the alignment field: the constant debates about the what and the how and the value of different attempts. Recently, we even had a whole sequence of debates, and since I first wrote this post Nate shared his take on why he can’t see any current work in the field actually tackling the problem. More generally, the culture of disagreement and debate and criticism is obvious to anyone reading the AF.

Jul 23, 2022
Robustness to Scaling Down: More Important Than I Thought
In Robustness To Scale, Scott Garrabrant presents three kinds of... well, robustness to scale: Robustness to scaling up, meaning that a solution to alignment keeps working as the AI gets better. Robustness to scaling down, meaning that a solution to alignment keeps working if the AI is not optimal or perfect. Robustness to relative scale, meaning that the solution to alignment doesn't rely on symmetrical capabilities between different subsystems.

Jul 20, 2022
How to Diversify Conceptual Alignment: the Model Behind Refine
We need far more conceptual AI alignment research approaches than we have now if we want to increase our chances to solve the alignment problem. However, the conceptual alignment field remains hard to access, and what feedback and mentorship there is focuses around few existing research directions rather than stimulating new ideas.

Jul 14, 2022
Circumventing interpretability: How to defeat mind-readers
Unaligned AI will have a convergent instrumental incentive to make its thoughts difficult for us to interpret. In this article, I discuss many ways that a capable AI might circumvent scalable interpretability methods and suggest a framework for thinking about these risks.

Jul 12, 2022
Mosaic and Palimpsests: Two Shapes of Research
In Old Masters and Young Geniuses, economist-turned-art-data-analyst David Galenson investigates a striking regularity in the careers of painters: art history and markets favors either their early pieces or the complete opposite — their last ones. From this pattern and additional data, Galenson extracts and defends a separation of creatives into two categories, two extremes of a spectrum: conceptual innovators (remembered as young geniuses) and experimental innovators (remembered as old masters).

Jun 6, 2022
Epistemological Vigilance for Alignment
Nothing hampers Science and Engineering like unchecked assumptions. As a concrete example of a field ridden with hidden premises, let's look at sociology. Sociologist must deal with the feedback of their object of study (people in social situations), their own social background, as well as the myriad of folk sociology notions floating in the memesphere.

Apr 9, 2022
Productive Mistakes, Not Perfect Answers
I wouldn’t bet on any current alignment proposal. Yet I think that the field is making progress and abounds with interesting opportunities to do even more, giving us a shot. Isn’t there a contradiction? No, because research progress so rarely looks like having a clearly correct insight that clarifies everything; instead it often looks like building on apparently unpromising ideas, or studying the structure of the problem.

Apr 8, 2022
We Are Conjecture, A New Alignment Research Startup
Conjecture is a new alignment startup founded by Connor Leahy, Sid Black and Gabriel Alfour, which aims to scale alignment research. We have VC backing from, among others, Nat Friedman, Daniel Gross, Patrick and John Collison, Arthur Breitman, Andrej Karpathy, and Sam Bankman-Fried. Our founders and early staff are mostly EleutherAI alumni and previously independent researchers like Adam Shimi. We are located in London.
Sign up to receive our newsletter and
updates on products and services.
Sign up to receive our newsletter and updates on products and services.
Sign up to receive our newsletter and updates on products and services.